
I'm trying to fully comprehend all I can concerning linked lists.
To do that, I decided making them (and making them work) in JS would be my best route.
I want to make sure no one sees any major flaws or careless mistakes (or pure dumbassery) in my code.
// Javascript Linked Lists v0.6
//ListNode class - for internal use (mostly)
class ListNode {
constructor (value, next = null) {
this.value = value;
this.next = next;
}
}
class LinkedList {
constructor (head = null) {
this.head = head;
this.length = 0;
}
add(el) {
let node = typeof el.value !== 'undefined' ? el : new ListNode(el);
if (typeof node.next === 'undefined'){
node.next = null;
}
let previous, current;
if (this.head === null){
node.previous = null;
this.head = node;
} else {
current = this.head;
while(current.next) {
previous = current;
current = current.next;
}
node.previous = current;
current.next = node;
}
this.length++;
}
remove(val) {
let current = this.head;
let previous;
if (current.value === val){
this.head = current.next;
} else {
while (current.value !== val){
previous = current;
current = current.next;
}
previous.next = current.next;
}
this.length--;
}
clear() {
this.head = null;
}
first() {
return this.head;
}
next() {
return this.head.next;
}
last() {
let lastNode = this.head
if (lastNode){
while (lastNode.next) {
lastNode = lastNode.next;
}
}
return lastNode;
}
pop(){
let node = this.last();
this.remove(node.value);
this.length--;
return node;
}
shift() {
let node = this.head;
this.remove (node.value)
this.length--;
return node;
}
unshift(val) {
let node = typeof val.value !== 'undefined' ? val : new ListNode(val);
let current = this.head;
node.next = current;
node.previous = null;
this.head = node;
this.length++;
return this.length;
}
addToHead(val) {
return this.unshift(val);
}
indexOf(val){
let current = this.head;
let i = -1;
while (current) {
i++;
if (current.value === val){
return i;
}
current = current.next;
}
return -1;
}
contains(val) {
return this.indexOf(val) > -1;
}
elementAt(i){
let current = this.head;
let count = 0;
while (count < i){
count++;
current = current.next;
}
return current.value;
}
addAt(ind, val){
let node = typeof val.value !== 'undefined' ? val : new ListNode(val);
let current = this.head;
let previous;
let currentIndex = 0;
if (ind > this.length){
return false;
}
if (ind === 0){
node.next = current;
node.previous = null;
this.head = node
} else {
while (currentIndex < ind){
currentIndex++;
previous = current;
current = current.next;
}
node.next = current;
node.previous = previous;
previous.next = node;
}
this.length++;
}
removeAt(index){
let current = this.head;
let previous;
let currentIndex = 0;
if (index < 0 || index >= this.length){
return null;
}
if (index === 0){
this.head = current.next;
} else {
while (currentIndex < index){
currentIndex++;
previous = current;
current = current.next;
}
previous.next = current.next;
}
this.length--;
return current.value;
}
count() {
return this.length;
}
isEmpty() {
return this.length === 0;
}
print(current = this.head) {
if (current){
console.log (current.value)
} else {
return;
}
this.print(current.next)
}
}
// create a linked list
let list = new LinkedList();
let a = "a";
let b = "b";
list.add(a)
list.add(b)
list.add("c")
let d = new ListNode("d");
list.add("e")
list.addAt(3, d)
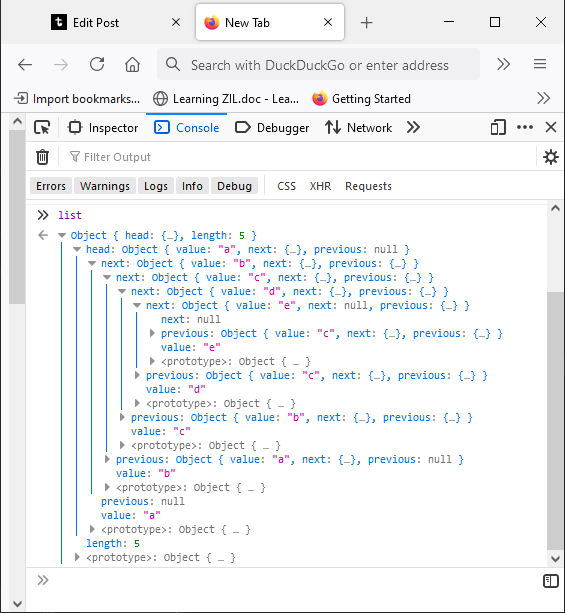

Looks right.
Although the last method is a little inefficient; in many applications, it's common to give the list object references to both the first and last nodes.
Also, what does this give you?
let list = new LinkedList();
list.add("foo")
list.add("bar")
list.add("baz")
list.add(list.next())
for (i=0 ; i<10 ; i++) {
console.log (list.shift().value)
}
console.log("Length: " + list.length);
It looks like some of your functions give the nodes a previous property, but this isn't used. Also, your length variable can easily get confused; because add increments it without checking if the added element is a ListNode which already has a next.
Javascript nerds would say that any list class should be Enumerable so that you can use it with foreach/map/grep/etc; but I think that's more complexity than you need.
Also, what does this give you?
Ruh roh!
I done been overlooking stuff!
First, I got an infinite loop (because I failed to add code to make sure there was something to shift).
Now, my length is -16. Hehehe.
What, oh what, have I done? (I'll be right back!)

You might want to look at some sort of unit testing. At its simplest, have a function that uses your code is different ways and tests the end result is what you think it should be. There are also unit testing frameworks, but that might be overkill here. It is a good habit to unit test code like this.
Hrmm... I don't know what I've done, but I apparently lack the concentration required to troubleshoot it right now.
I shall return, though -- either with a "fix" or with questions.
You might want to look at some sort of unit testing.
Ah, I posted that last post without refreshing the page and didn't see this.
It does sound a like a good idea.
First, I got an infinite loop (because I failed to add code to make sure there was something to shift).
I suspect you ended up with an infinite loop because the list has two elements whose next properties point to each other :)
LISP-style lists can handle this, because you can have lists that merge. It just means that you can't loop over them, because infinite lists exist. And, of course, the length property isn't meaningful.
But most list libraries use a double-linked list (DLL), where each element has both next and prev properties.
When your add function comes to add a new element node after an existing element previous, you would do something like:
if (node.prev) {
node.prev.next = node.next;
}
if (node.next) {
node.next.prev = node.prev;
}
node.next = previous.next;
if (previous.next) {
previous.next.prev = node;
}
previous.next = node;
node.prev = previous;
which removes node from any list it's previously been in.
Or, depending on how you're going to use it, you might allow the node and all its successors to be moved as a unit. But in this case, it might be a good idea to check that the added node isn't already in this list; for which you would probably need a reference to the list object.
Okay, I still have to read most of the stuff posted after the first example that threw me for an infinite loop.
Here's that code (slightly modified, so as to avoid an error):
list = new LinkedList();
list.add("foo")
list.add("bar")
list.add("baz")
list.add(list.next())
for (i=0 ; i<10 ; i++) {
console.log (list.shift()?.value) // added the question mark to avoid an error when the list is empty
}
console.log("Length: " + list.length);
OUTPUT
foo debugger eval code:7:11
bar debugger eval code:7:11
baz debugger eval code:7:11
bar debugger eval code:7:11
undefined debugger eval code:7:11
undefined debugger eval code:7:11
undefined debugger eval code:7:11
undefined debugger eval code:7:11
undefined debugger eval code:7:11
undefined debugger eval code:7:11
Length: 0
Linked Lists v0.7
// Javascript Linked Lists v0.7
//ListNode class - for internal use (mostly)
class ListNode {
constructor (value, next = null) {
this.value = value;
this.next = next;
}
}
class LinkedList {
constructor (head = null) {
this.head = head;
this.length = 0;
}
add(el) {
let node = typeof el.value !== 'undefined' ? {value: el.value} : new ListNode(el);
//if (typeof node.next === 'undefined'){
node.next = null;
//}
let previous, current;
if (this.head === null){
node.previous = null;
this.head = node;
} else {
current = this.head;
while(current.next) {
previous = current;
current = current.next;
}
node.previous = current;
current.next = node;
}
this.length++;
}
remove(val) {
let current = this.head;
let previous;
if (current.value === val){
this.head = current.next;
} else {
while (current.value !== val){
previous = current;
current = current.next;
}
previous.next = current.next;
}
this.length--;
}
clear() {
this.head = null;
}
first() {
return this.head;
}
next() {
return this.head.next;
}
last() {
let lastNode = this.head
if (lastNode){
while (lastNode.next) {
lastNode = lastNode.next;
}
}
return lastNode;
}
pop(){
let node = this.last();
this.remove(node.value);
this.length--;
return node;
}
shift() {
if (!this.head){
return null;
}
let node = this.head;
this.head = this.head.next;
this.length--;
return node;
}
unshift(val) {
let node = typeof val.value !== 'undefined' ? val : new ListNode(val);
let current = this.head;
node.next = current;
node.previous = null;
this.head = node
this.length++;
return this.length;
}
addToHead(val) {
return this.unshift(val);
}
indexOf(val){
let current = this.head;
let i = -1;
while (current) {
i++;
if (current.value === val){
return i;
}
current = current.next;
}
return -1;
}
contains(val) {
return this.indexOf(val) > -1;
}
elementAt(i){
let current = this.head;
let count = 0;
while (count < i){
count++;
current = current.next;
}
return current.value;
}
addAt(ind, val){
let node = typeof val.value !== 'undefined' ? val : new ListNode(val);
let current = this.head;
let previous;
let currentIndex = 0;
if (ind > this.length){
return false;
}
if (ind === 0){
node.next = current;
node.previous = null;
this.head = node
} else {
while (currentIndex < ind){
currentIndex++;
previous = current;
current = current.next;
}
node.next = current;
node.previous = previous;
previous.next = node;
}
this.length++;
}
removeAt(index){
let current = this.head;
let previous;
let currentIndex = 0;
if (index < 0 || index >= this.length){
return null;
}
if (index === 0){
this.head = current.next;
} else {
while (currentIndex < index){
currentIndex++;
previous = current;
current = current.next;
}
previous.next = current.next;
}
this.length--;
return current.value;
}
count() {
return this.length;
}
isEmpty() {
return this.length === 0;
}
print(current = this.head) {
if (current){
console.log (current.value)
} else {
return;
}
this.print(current.next)
}
}
Now I shall scroll up and read everything after that code first appeared. I've surely got more fish to fry.
Can I do anything special with this that I couldn't otherwise do with an array in JS?
With a basic list, probably not. But for certain applications…
In my case, I'm rolling my own linked list because I'm using a slightly unorthodox method to remove elements from the list:
Removal:
this.next.prev = this.prev this.prev.next = this.next
And to undo removal:
this.prev.next = this.next.prev = this
It's a lot faster than standard arrays for tasks where you'll be repeatedly deleting and undeleting elements, but you don't need to add anything new. Two integer assignments and you're done :)
Also, cyclical linked lists (the last element's next points to the first element again) can be used in interesting ways. For example, if you want to loop over a list starting with a specified element, you can easily loop until you get back to the start point. No need to keep track of an index, or create a temporary data structure to collate your array.
Some of these are rather unusual tasks, that you probably won't need often. The array is a general-purpose tool, so it's often quite inefficient compared to a specific type of list made for a specific task. So it's good to understand how these things work under the hood, in case you ever need them :)
Somewhat irrelevant, but here's an example of a case where linked lists run a whole lot faster than the hybrid lists that JS uses. Written in Perl, but you can probably see what it's supposed to do. I really, really hope I've not made any dumb mistakes here.
This is a table implemented as a 2-dimensional linked list (with each cell being a hashref with 'up', 'down', 'left', and 'right' pointers; as well as 'action' pointing to the row header, and 'header' the column header), and where the row/column headers are hashrefs with either "top" and "bottom", or "first" and "last" pointers. In my implementation, $header->{last}->{right} is the same as $header->{first} - all rows and columns are infinite loops, which makes it a little faster to loop over them starting with an arbitrary element.
sub do_solve {
my ($colhead, $solution) = @_;
if ($shortest_first) {
my $shortest = $colhead;
for (my $col = $colhead->{right} ; $col != $colhead ; $col = $col->{right}) {
if ($col->{count} < $shortest->{count}) {
$shortest = $col;
}
}
$colhead = $shortest;
}
my $option = $colhead->{top};
while ($option = $option->{down}) {
choose_row($option, $solution);
last if ($option == $colhead->{bottom});
}
}
sub choose_row {
my ($startcell, $solution) = @_;
my $reason;
$startcell->{action}->{prev} = $solution;
for (my $cell = $startcell->{left} ; $cell != $startcell ; $cell = $cell->{left}) {
if ($reason = remove_column($cell)) {
# failed to make the choice, so undo
while ($startcell != $cell = $cell->{right}) {
unremove_column($cell);
}
return $reason;
}
}
# Removed the row without errors
# So if this header is the last one, we have a valid solution
my $header = $startcell->{header};
if ($header->{left} == $header) {
output_solution($startcell->{action});
} else {
# Not finished yet, so remove the column and do the next one
unless ($reason = remove_column($startcell)) {
do_solve($header->{right}, $startcell->{action});
unremove_column($startcell);
}
}
for (my $cell=$startcell->{right} ; $cell != $startcell ; $cell = $cell->{right}) {
unremove_column($cell);
}
return $reason;
}
sub remove_row {
my $startcell = shift;
for(my $cell=$startcell->{right} ; $cell != $startcell ; $cell = $cell->{right}) {
if ($cell->{up} == $cell) {
# Only cell in the column - stop part way and undo the failed transaction
my $reason = "Failed to meet constraint " . $cell->{header}->{name};
while ($startcell != $cell = $cell->{left}) {
$cell->{up}->{down} = $cell->{down};
$cell->{down}->{up} = $cell->{up};
$cell->{header}->{count}++;
}
return $reason;
}
$cell->{up}->{down} = $cell->{down};
$cell->{down}->{up} = $cell->{up};
$cell->{header}->{count}--;
}
}
sub unremove_row {
my $startcell = shift;
for(my $cell=$startcell->{left} ; $cell != $startcell ; $cell = $cell->{left}) {
$cell->{up}->{down} = $cell;
$cell->{down}->{up} = $cell;
$cell->{header}->{count}++;
}
}
sub remove_column {
my $startcell = shift;
my $reason;
for (my $cell=$startcell->{down} ; $cell != $startcell ; $cell=$cell->{down}) {
if ($reason = remove_row($cell)) {
# failed to remove; so undo back to the start of the transaction
while ($startcell != $cell = $cell->{up}) {
unremove_row($cell);
}
return $reason;
}
}
$startcell->{header}->{left}->{right} = $startcell->{header}->{right};
$startcell->{header}->{right}->{left} = $startcell->{header}->{left};
}
sub unremove_column {
my $startcell = shift;
$startcell->{header}->{left}->{right} = $startcell;
$startcell->{header}->{right}->{left} = $startcell;
for (my $cell=$startcell->{up} ; $cell != $startcell ; $cell=$cell->{up}) {
unremove_row($cell);
}
}
In case you need help understanding Perl:
@_. The shift function operates on @_ if you don't give it a parameter.$somevar is a scalar variable (float, int, string, or reference)@somevar is an array (list). $somevar[0] is its first element.%somevar is a hash (dictionary). $somevar{key} is an element of it. The key is assumed to be a string unless it contains any symbol characters.
@somehash{@array_of_keys), which I think is pretty neat.$somevar is a reference to another variable, you can get the variable it points to using $$somevar, @$somevar, %$somevar or similar.
@{$somearray[4]}$somearray[4]->{somekey} is the "somekey" element of the hash pointed to by the 4th element of @somearray.["apple", "banana", "fish"] returns a reference to an array, and {"fruit" => "apple", "fish" => "cod"} returns a reference to a hash.What do you think?
In case you need help understanding Perl
I did need this! I was scrolling through the code, and I was just about to start grumbling to myself about needing to go learn a little Perl when I found the explanation you added.
This seems like a sidetrack, but it's not:
I'm nearly done with my homemade text adventure written in Vanilla Javascript. (In fact, I would be done, had I not decided to add code which allows the NPCs to take commands. Most of the NPC stuff is working. Just a few wrinkles left to find and iron out. Anyway...)
A few days ago, I decided I should rewrite the whole thing in the current version of BASIC, just for fun and also to negate any thoughts about cross-browser compatibility. Well, the current version of BASIC doesn't look anything like the BASIC that was on my Tandy CC2. In fact, the new BASIC looks a lot like C#. So, I said [CENSORED] the new BASIC, and . . .
Two days ago, I started learning C++ whenever I felt like taking a break from my Vanilla JS project. I think I know enough about C++ now to be dangerous. It looks like I cannot have a "mixed" array. Meaning it looks like my array has to have all the same types of keys: int, double, string, etc. I also have to declare an array's maximum length. This leads me to believe. . .
I definitely need to really learn about tables, linked lists and hash tables, and two-dimensional arrays, too!
...and, just like it always works, you happen to post about the very thing I need to learn about just when I need to see it.
The Force is pretty awesome.
Good luck with the C++ :-)
In case you're curious; the perl code above is a somewhat-optimised way of solving a covering problem. Basically, it takes a table/matrix, and finds a subset of the rows which contain exactly one cell in each column.
It picks the column with fewest options and loops over it choosing the rows. For each row, it deletes from the table all other rows that share a column with it. If this leaves a different column with no rows in it, we've failed so undo and go back to the . If there are no columns left, we succeeded. Otherwise, we continue by running the solver on a different column.
This algorithm requires a lot of backtracking. So we need a method of maintaining an 'undo' buffer that doesn't take a ton of memory storing everything we've tried, and doesn't need to keep allocating new memory for temporary things. In this case, it's pretty fast because of the "dancing links" - each cell has pointers to the cells that were next to it in the row or column before it was deleted, and when we undelete we're always rolling back to the same point we were at before, so we're reversing the order of deletions. So we can just do cell.prev.next = cell.next.prev = cell to put the cell back where it was. No if, no calculations, just a straight assignment.
Among other things, you can use it for solving sudoku. The row headers are actions like "Place 5 in cell (7,2)" and column headers are conditions like "Placed a 5 in row 2", "Placed a 5 in column 7", "Placed a 5 in box 3", and "Placed a digit in (7,2)" that have to be satisfied exactly once to make a correct solution. This makes a 324×729 matrix of options, (smaller if you have given digits), so I'm sure you can see why having the loop run fast is a good thing.
the perl code above . . .
I was almost ready for the stuff we've covered in ZIL/MDL -- almost ready enough to get through it all. So, I guess "barely ready" is the proper terminology.
I'm not ready for this stuff yet, though. I think I'll be forced to learn enough to be ready for it if I get far enough in C++, though. At that time, I shall return and learn from these posts (trust me; I will).
Good luck with the C++ :-)
It looks mostly like JS. (Or I guess JS looks mostly like C++; huh?)
The big differences I've seen so far are:
forEach (only for, which I know how to use, so meh)Also, I apparently need to expose myself to Sudoku, since 80% of the examples I see concerning complex code use Sudoku to illustrate. :o)
Good luck with the C++ :-)
Am I better off just sticking to JS and learning as much about it as possible?
After seriously fooling with C++ for a couple of days, I understand pointers and addresses now -- at least on an elementary level.
...and tables, too.
I was thinking I should go with C++, as I wish to learn the most universal language, and I thought C++ would have fewer cross-platform concerns than JS has cross-browser concerns. Now, though, I'm thinking:
Also, Python, Perl, Ruby, etc., aren't installed on most machines (I don't think); so, it seems like those languages are like "extra-credit" languages, for lack of a better term.
I think maybe I should just learn half of what mrangel knows about JS, and then I'd have accomplished something.
Am I wrong? Can C++ do something we can't do with JS, as far as text adventures are concerned?
JavaScript does not have much cross-browser issues nowadays. I have taken JavaScript ES6 (ECMAScript 2015) as my standard, and I reckon if it is in that, at least 98% of users will be fine, and that figure will increase. Besides that, I ignore browser issues.
C++ I suspect will have more cross platform issues, like for example, the size of an integer can be different on a 32-bit computer compared to 64-bit - but then, you have something like 20 different integer types to choose from, and only some depend on the platform.
Your C++ code is cross-platform, but you have one .exe for Apple, another for Windows, another for Linux, and ideally you would test in each environment. Plus, some people will be reluctant to download a .exe from a random source because of the security risk. This is a big reason why I went to JavaScript; the browser is your player, and everyone already has the player installed.
Worth noting that Inform uses JavaScript too when output to a webpage. Parchment and Quixe are both JavaScript programs that will load an Inform file and play it.
arrays have to include all the same types (a good reason to use linked lists, I wot)
Ahh, welcome to the wonder of strongly typed languages :)
If you want a list with different types, you'll probably end up working with templates and generics, which can be a real pain.
Languages with dynamic types tend to be more flexible, and easier to Just Do Stuff without building a structure around it first. The big difference is usually efficiency.
In JS, you come to an expression like a + b. If the variables are strings, they're catenated. If they're ints, you add them together. If they're different types, a fancy algorithm has to determine what type to convert them to before adding or catenating.
In C/C++/Java, when the compiler sees a + b, it looks at the types of those variables and selects an appropriate function to combine them. This is done at compile time, so when the code actually runs the + has already been replaced by a piece of code that adds two numbers together, or whatever. Just doing addition is faster than checking the types every time.
So, JS does almost everything C++ can do now, but more slowly, because a function doesn't know what types its arguments are until it's running and it needs to check every time.
JavaScript does not have much cross-browser issues nowadays.
True. Most of my issues involve the way the HTML is displayed (and whether or not the player is using a mobile browser).
That's not really anything to do with JS, I don't reckon. :)
C++ I suspect will have more cross platform issues, like for example, the size of an integer can be different on a 32-bit computer compared to 64-bit - but then, you have something like 20 different integer types to choose from, and only some depend on the platform.
You ain't just whistling Dixie! I found this out on Day 1.
Your C++ code is cross-platform, but you have one .exe for Apple, another for Windows, another for Linux
Well, pretty much, except one Linux binary is not enough. There are multiple "flavors" of Linux, and they don't all behave the same way. That's why (come to find out) I usually have to build from the source code when installing a release of something for Linux on GitHub.
Worth noting that Inform uses JavaScript too when output to a webpage. Parchment and Quixe are both JavaScript programs that will load an Inform file and play it.
Yeah, neither can handle the help menu properly in a browser, and Parchment doesn't save progress worth a crap (see the many threads on this site asking how to save progress in the Inform port of Zork).
Now that I think about it, after making the INVISICLUES style menu work in Quest, I think I could probably fix their issue with the menus -- if their code wasn't a jumbled mess. Even after converting it from Base64 and running it through btoa() (which is what I believe I had to do), the JS is in-line, and the line is a million kilometers long! Egads!!!
All that aside, it does look to me like C++ is more tedious than it is 'better than JS'.
Plus, some people will be reluctant to download a .exe from a random source because of the security risk.
Yeah, that's definitely true, too.
This is a big reason why I went to JavaScript; the browser is your player, and everyone already has the player installed.
A very good call, good sir!
Ahh, welcome to the wonder of strongly typed languages :)
Ha ha! Yeah...
It is definitely educational, though!
In JS, you come to an expression like
a + b. . .
In C/C++/Java, when the compiler sees
a + b. . .
Hey. . . Is that what the Just In Time thing means?
the JS is in-line, and the line is a million kilometers long! Egads!!!
This is why I like Chrome.
The developer console is pretty good at formatting compressed javascript in a readable way.
Hey. . . Is that what the Just In Time thing means?
Not quite. As far as I understand it, JIT means a language operates in a way that's a cross between a compiled language and an interpreter. Like the JS engine tries to analyse your code while it's running, and find better compilation paths if it can spot where the bottlenecks are. This is a kind of hybrid of interpreter flexibility and compiled speed.